Every business focusing on DevOps and Cloud should have some kind of a containerization tool in their technology stack, with the most popular being Docker. Docker alleviates the problems of porting your application to different environments, operating systems and machines by creating a wrapper around the application with predefined instructions on how to run the application. It is a standard, so it is easily integrated with countless other services such as Kubernetes or Docker Swarm. Let us look at the basics and start with implementing Docker in the DevOps pipeline.
Docker basics
To effectively incorporate Docker into your pipeline, you need:
- Dockerfile – a recipe on how to create a Docker image
- Docker registry – a storage for Docker images. (Nexus, Gitlab Registry,..).
- Machine running Docker Daemon – where Docker images are executed
- Pipeline – Recommended for creating Docker images
A Dockerfile accelerates and optimizes application deployment. Once a Docker image is created, it can be deployed on any Docker-compatible machine. An example of a basic Dockerfile (blueprint) running a python script will look like this
FROM ubuntu:22.04
COPY . /app
CMD python /app/app.py
The Docker first pulls the base image of Ubuntu, which serves as the base layer. Copies the content of your application inside the filesystem on path /app and sets the starting command when running the docker image to run your script. Each time you run the docker image and create a docker container, it will perform the CMD (or ENTRYPOINT) code.
Keep in mind that where as you can use the same docker registry for different applications, this does not apply to the Dockerfile, as different applications most often have different Dockerfiles.
Beware of the most common pitfall
There are many pitfalls while building the best and most optimal docker image, but we will take a look at the most common – having a redundantly large docker image.
Keep the Dockerfile as minimalistic as it needs to be. Oftentimes, we come across a massive Dockerfile which updates the underlying image, downloads multiple libraries in multiple separated RUN commands and builds the application artifacts. So what is wrong?
- Updating the underlying image. – Choose an up-to-date base image or customize your own to avoid updating libraries post-deployment.
- Chain the RUN commands – Each RUN command adds a new docker layer to further bloat your image size. By having only one RUN command, you will create only one layer, thus reducing size.
- Building artifacts inside Dockerfile – Always build artifacts outside of your Dockerfile. The application does not run from the code you write, but from the built application (.exe, .war, etc.).
Simple steps such as building the artifacts outside of the Dockerfile definition and building them inside a CI/CD pipeline can save you sometimes even 90 percent of storage.
Into the pipeline
A general minimalistic pipeline for any kind of an application should follow three steps, also called stages in a CI/CD pipeline:
- Build Application
- Build & Push Image
- Deploy application
These steps follow a simple workflow as if you were running the application on your local machine. First you build the application, which if you are a javascript developer you may know it as the dist/ folder where the artifacts are stored. Then you create a docker image via the Dockerfile aforementioned. This creates a wrapper around the app and makes it platform agnostic and the next step is to push this image to a remote registry, so it can be used either by your colleagues or as a deployment to servers.
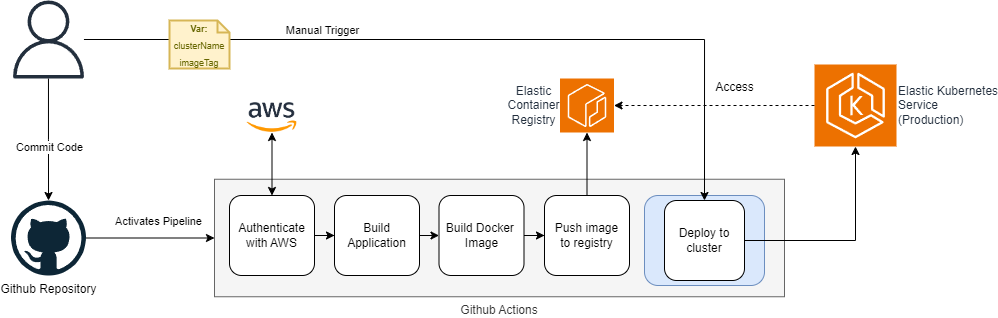
In the image we can see a simple pipeline including the Docker stages. The build stage is taken out of the Docker stage and resides as a separate step. The Docker image is built with only the artifacts of the applications and then pushed to a private Elastic Container Registry. As we dont want the application to be always deployed automatically, we have added a manual step where the user can trigger the deployment. EKS (kubernetes on aws) has access to the ECR, pulls the image from the registry and spins up the application, with no manual steps needed (aside from running the job).
So what are the benefits?
The power of Docker and containerisation in DevOps is not the technology itself, but the limitless possibilities and integrations we may use after implementing it to our workflow. We can look at for example at scaling an application on an infrastructure without any form of containerisation and a Kubernetes infrastructure with Docker in mind as the underlying engine.
In the infrastructure lacking Docker, if we would like to scale an application (create more replicas), we would need to manually copy the application to the target machine which handles the replica. If we needed to scale down the application, we would need to access the target machine once again and then delete the application. During an update, we would need to manually update each code in each target virtual machine which can be a tedious process.

Pavol Krajkovic
DevOps Specialist and Consultant

